Sobre el Proyecto
El proyecto La GPU como Motor de Cómputo Moderno: De los Gráficos a la Inteligencia Artificial consiste en un análisis técnico profundo sobre la transformación de la Unidad de Procesamiento Gráfico (GPU). Originalmente diseñada como un hardware de función fija para renderizar imágenes en pantalla, la GPU ha evolucionado hacia arquitecturas altamente programables de paralelismo masivo (GPGPU).
El estudio aborda desde los fundamentos lógicos que diferencian a la CPU de la GPU (enfoque de latencia frente a rendimiento o throughput), pasando por la microarquitectura interna de los núcleos CUDA, Tensor y Ray Tracing, hasta los aspectos físicos de conexión (PCIe 5.0), alimentación (12VHPWR) y disipación térmica (evitando el thermal throttling). Asimismo, se examina de manera detallada el subsistema de memoria VRAM y la relación simbiótica de la tarjeta gráfica con las tecnologías de panel del monitor (IPS, VA, OLED) y sincronización adaptativa (G-Sync, FreeSync, VRR).
Filosofías de Procesamiento: CPU vs GPU
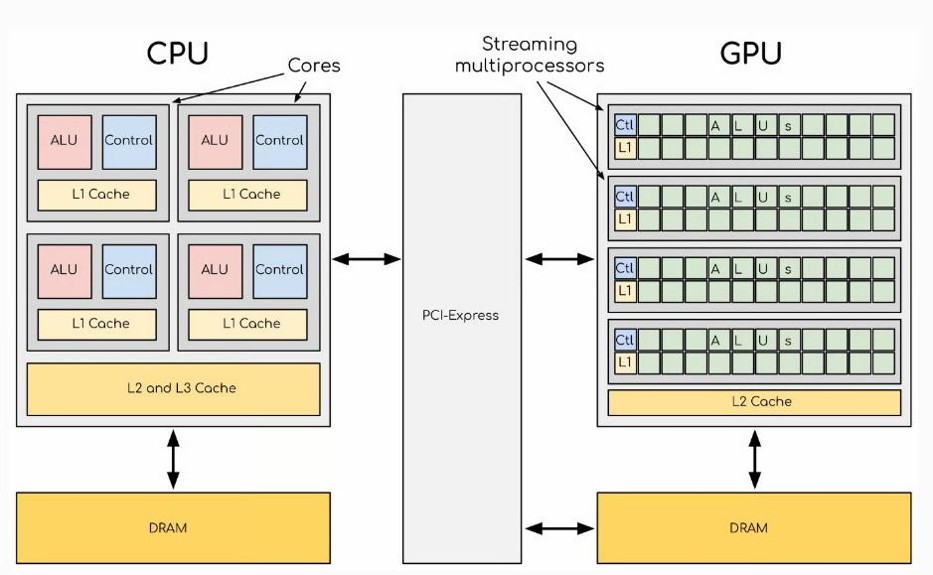
El diseño arquitectónico de una CPU y una GPU responde a problemas de cómputo radicalmente distintos. La CPU está optimizada para la reducción de la latencia, mientras que la GPU se enfoca en maximizar el rendimiento total (throughput).
Latencia Frente a Rendimiento (Throughput)
La CPU cuenta con pocos núcleos muy complejos y veloces, asistidos por grandes cachés y lógica de predicción de saltos. Su objetivo es ejecutar un único hilo secuencial lo más rápido posible.
Por el contrario, la GPU sacrifica la velocidad individual del núcleo y la complejidad lógica para integrar miles de núcleos de cálculo simples. Esto le permite procesar flujos masivos de datos de forma paralela.
Modelos de Paralelismo: SIMD vs SIMT
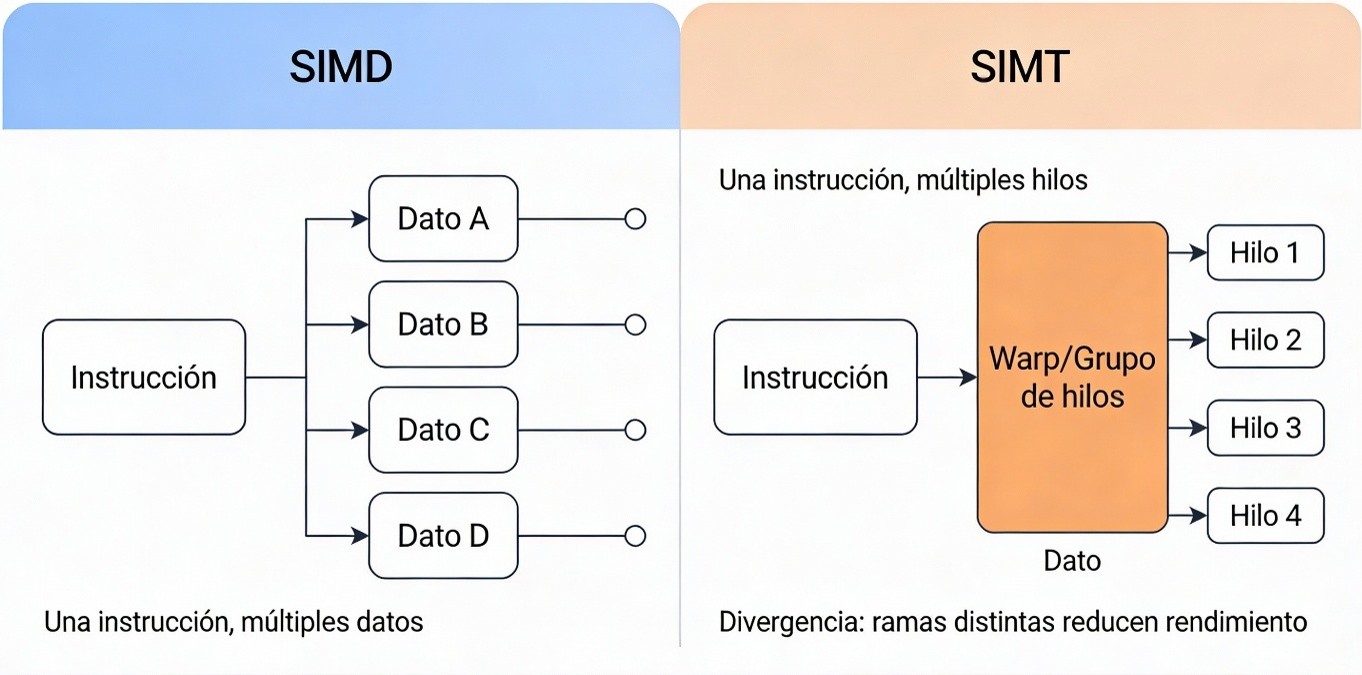
- SIMD (Single Instruction, Multiple Data): Un único controlador emite una sola instrucción que se ejecuta simultáneamente sobre múltiples datos. Es un paralelismo rígido, altamente eficiente para vectores homogéneos pero vulnerable a la divergencia lógica.
- SIMT (Single Instruction, Multiple Threads): Modelo introducido por NVIDIA que organiza la ejecución en grupos de hilos (warps o wavefronts). Cada hilo puede tomar decisiones lógicas independientes. Si hay divergencias, el hardware serializa temporalmente las ramas, pero mantiene un alto grado de flexibilidad indispensable para Ray Tracing o redes neuronales.
La Analogía del Rendimiento
Microarquitectura de Núcleos y Pipeline Gráfico
Las GPUs actuales no disponen de núcleos genéricos, sino de unidades especializadas integradas en el silicio para resolver cálculos geométricos, matriciales y físicos de forma independiente.
Núcleos Especializados
- Núcleos CUDA / Stream Processors: Encargados de operaciones aritméticas tradicionales de coma flotante (FP32/FP64) y enteros (INT32) necesarias para el sombreado y renderizado gráfico.
- Núcleos Tensor: Unidades optimizadas para la multiplicación de matrices en un solo ciclo de reloj. Operan con precisión mixta (FP16, BF16, INT8), acelerando el entrenamiento de modelos de Inteligencia Artificial (Deep Learning) y técnicas de escalado como DLSS.
- Núcleos RT (Ray Tracing): Aceleradores por hardware dedicados a calcular las colisiones e intersecciones de rayos sobre la jerarquía de volumen envolvente (BVH). Permiten simular la luz físicamente en tiempo real sin saturar los núcleos de sombreado.
El Pipeline Gráfico
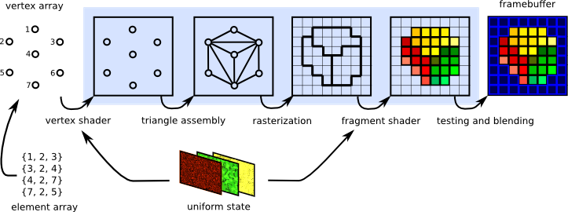
El flujo que transforma datos geométricos matemáticos en píxeles rasterizados sigue una cadena lógica altamente optimizada:
graph LR
A["Datos (CPU)"] --> B["Vertex Shader"]
B --> C["Primitive Assembly"]
C --> D["Rasterización"]
D --> E["Fragment Shader"]
E --> F["Tests & Framebuffer"]
- Vertex Shader: Transforma las coordenadas de los vértices 3D al espacio bidimensional de pantalla.
- Ensamblado de Primitivas: Une los vértices para formar triángulos básicos y realiza el descarte (clipping) de los que están fuera de cámara.
- Rasterización: Convierte los triángulos vectoriales continuos en una cuadrícula discreta de fragmentos (candidatos a píxeles).
- Fragment Shader: Aplica el texturizado, iluminación y color final a cada fragmento.
- Tests y Salida: Realiza comprobaciones de profundidad (depth test) y escribe la imagen final en el framebuffer de la VRAM.
Jerarquía de Memoria VRAM y Ancho de Banda
La GPU genera datos a tal velocidad que la RAM del sistema (cuello de botella por latencia y bus) resulta inviable. La VRAM (Video RAM) está soldada junto al chip gráfico para ofrecer anchos de banda masivos.
Bus de Datos y Ancho de Banda
El rendimiento real del subsistema de memoria no solo depende de la capacidad (en Gigabytes), sino del ancho de bus (desde 128 bits hasta 384 bits) y el tipo de memoria utilizada (GDDR6 o GDDR6X).
$$\text{Ancho de Banda (GB/s)} = \frac{\text{Frecuencia Efectiva (Hz)} \times \text{Ancho del Bus (bits)}}{8}$$
Una GPU de gama alta con bus de 384 bits puede transferir más de 1.000 GB/s, evitando que los núcleos de cálculo entren en estado de espera.
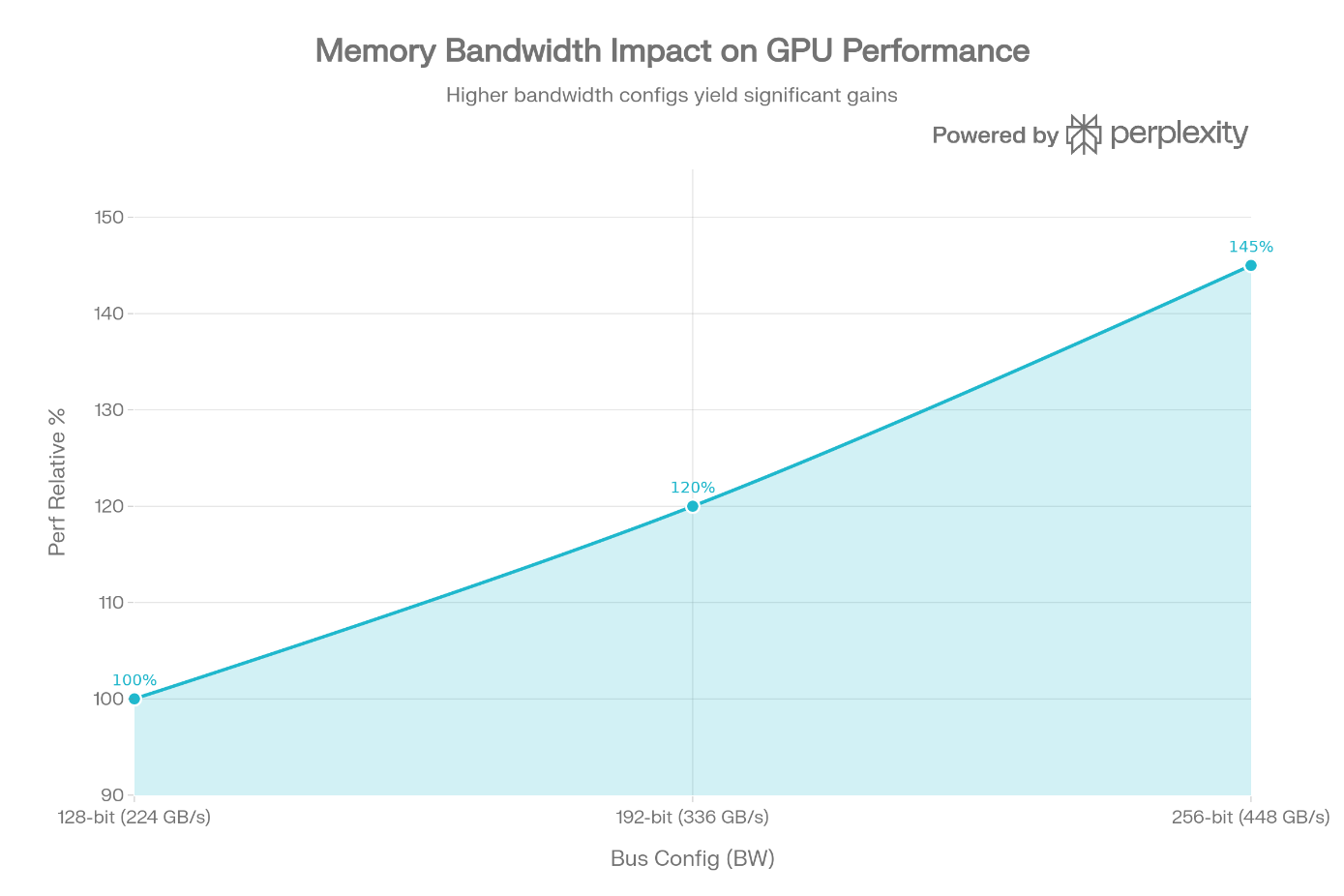
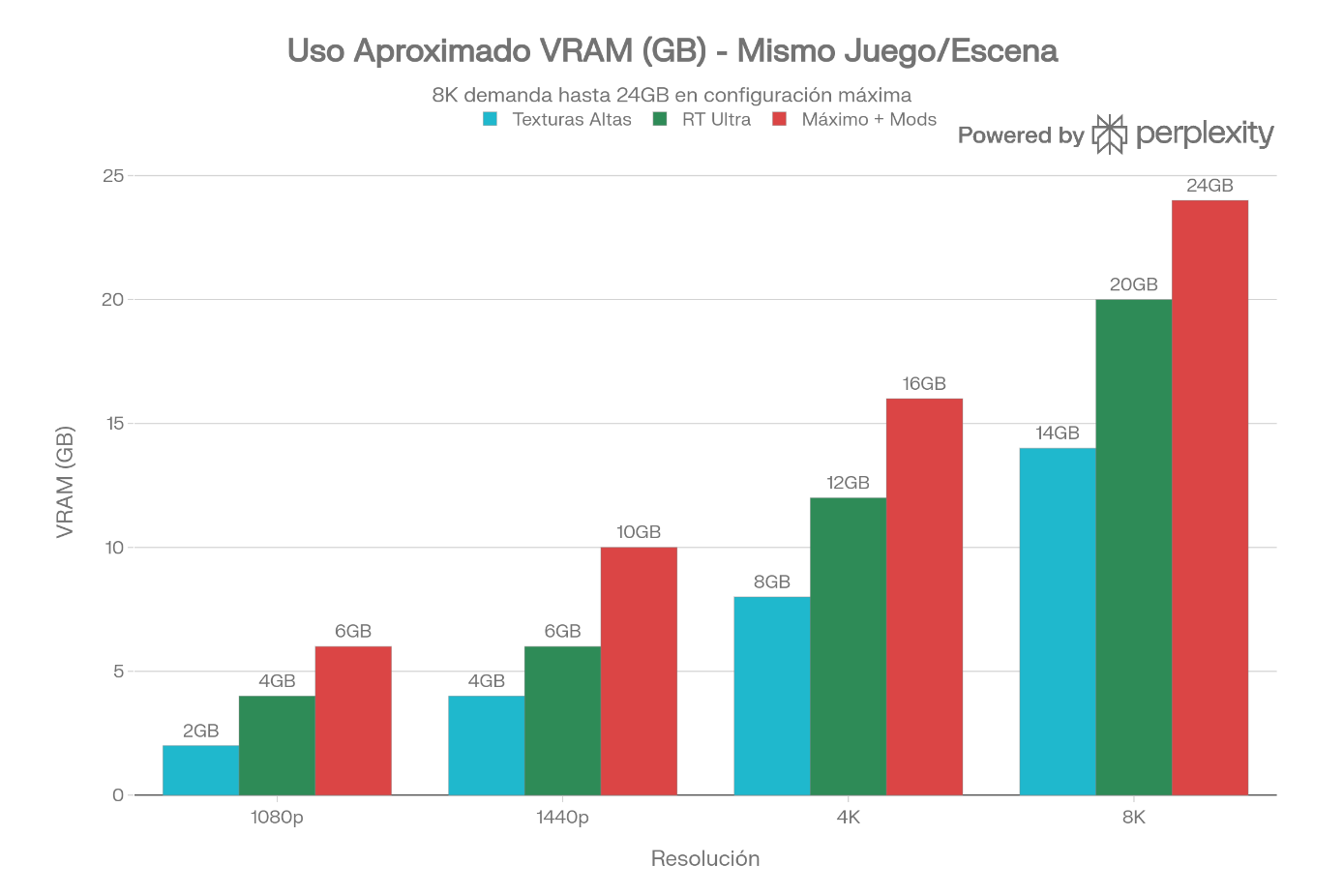
Escalado por Resolución e Ineficiencia (Stuttering)
Al incrementar la resolución (de 1080p a 4K), el tamaño del búfer de imagen y las texturas en alta definición crece de forma exponencial.
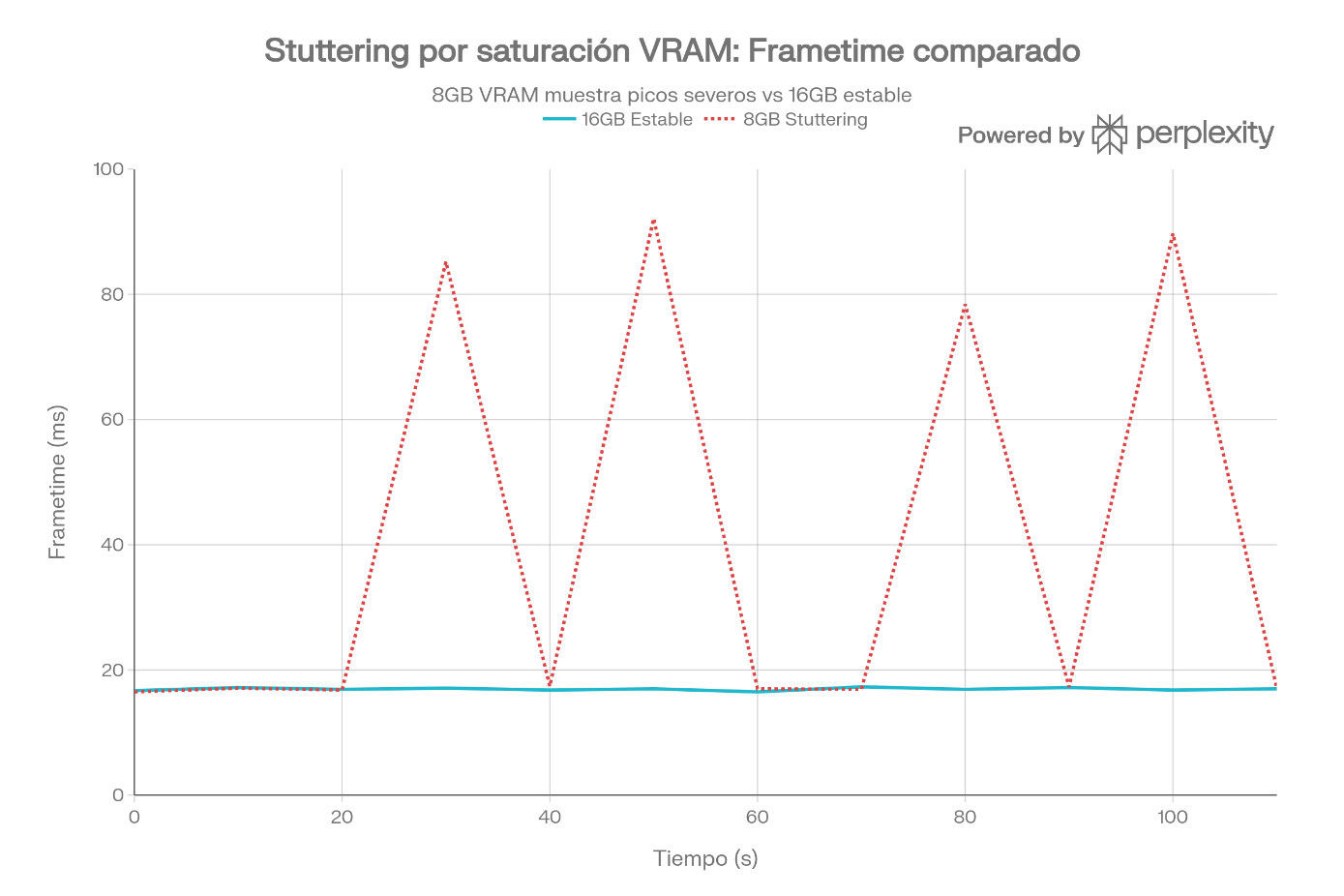
Si los requisitos de una escena superan la capacidad física de la VRAM, el sistema se ve obligado a transferir datos a la RAM convencional del sistema a través del bus PCI Express. Este proceso (swapping) provoca microparones críticos en el tiempo de fotograma, fenómeno conocido como stuttering.
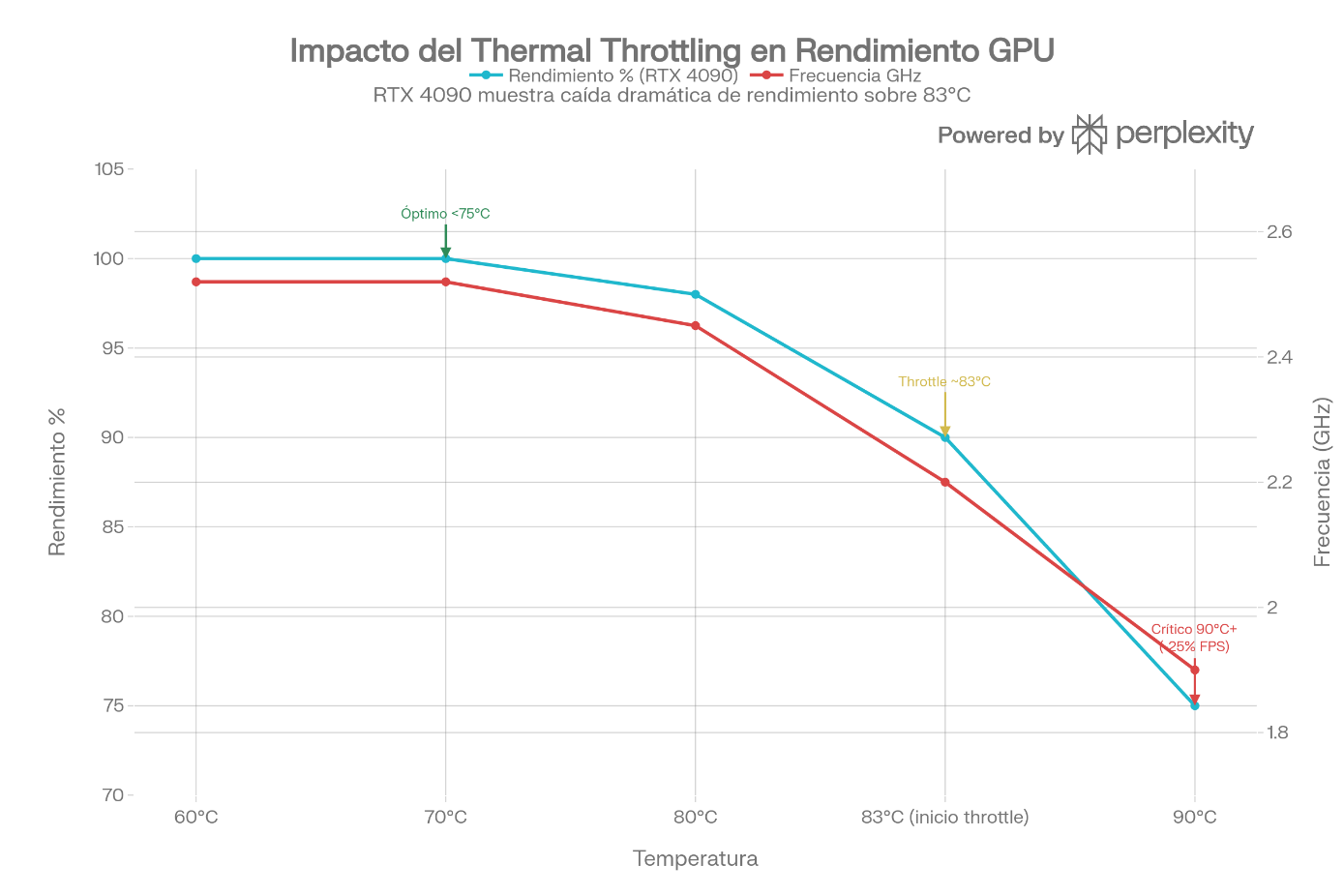
Integración Física y Sinergia con el Monitor
El rendimiento del silicio se ve directamente limitado por la interfaz física y la disipación térmica, y carece de sentido si el monitor no es capaz de representarlo de forma fiel.
Interfaz PCIe, Alimentación y Gestión Térmica
Las GPUs modernas de alto rendimiento exigen una integración robusta a nivel de placa base y suministro eléctrico:
- PCIe x16: Interfaz estándar para el intercambio de datos. El paso de PCIe 3.0 a PCIe 4.0/5.0 duplica el ancho de banda por línea (hasta 64 GB/s en x16), crucial para el entrenamiento de IA y la carga de texturas ultrarrápida (DirectStorage).
- Alimentación (12VHPWR): El nuevo conector de 16 pines suministra hasta 600W de potencia, requiriendo fuentes ATX 3.0 con cables dedicados para evitar picos de inestabilidad.
- Refrigeración: Debido al consumo TGP (Total Graphics Power) de hasta 450W en dGPUs dedicadas, los disipadores axiales o sistemas líquidos son vitales. Si la temperatura alcanza el límite térmico establecido por firmware, se activa el thermal throttling, reduciendo drásticamente la frecuencia del reloj para salvar el integrado.
Tecnologías de Panel del Monitor
El monitor es el traductor final de la GPU. La elección de la tecnología de panel define la experiencia cromática e inmersiva:
| Tipo de Panel | Ventaja Principal | Límite Técnico / Defecto | Escenario Recomendado |
|---|---|---|---|
| TN (Twisted Nematic) | - Tiempo de respuesta ultrabajo (<1ms). | - Ángulos de visión reducidos. - Colores apagados. |
eSports competitivos de alta frecuencia (360Hz+). |
| IPS (In-Plane Switching) | - Excelente fidelidad de color. - Ángulos de visión de 178°. |
- IPS Glow en las esquinas. - Contraste limitado (1000:1). |
Diseño gráfico, edición de vídeo y gaming equilibrado. |
| VA (Vertical Alignment) | - Alto contraste nativo (3000:1+). - Negros profundos. |
- Black smearing (estelas oscuras) en transiciones rápidas. | Contenido multimedia y simulación inmersiva. |
| OLED (Organic LED) | - Contraste infinito (píxeles autoemisivos). - Tiempos de respuesta de 0.03ms. |
- Riesgo de burn-in a largo plazo. - Brillo medio limitado (ABL). |
Entusiasta, HDR real y máxima calidad visual. |
Sincronización Adaptativa: Evitando el Screen Tearing
Cuando la GPU y el monitor no trabajan en paralelo, surge el screen tearing (rupturas horizontales de imagen provocadas por el envío de frames a destiempo).

Para solucionarlo sin el retraso de entrada (input lag) del antiguo V-Sync, se emplean tecnologías de frecuencia de refresco variable (VRR):
- NVIDIA G-Sync: Módulo físico propietario que adapta dinámicamente los Hz del monitor a los fotogramas entregados por la GPU en tiempo real.
- AMD FreeSync: Estándar abierto basado en el protocolo VESA Adaptive-Sync, libre de licencias y compatible con la mayoría de monitores modernos.
Anexo: Horizontes Expandidos (La Era GPGPU)
La evolución de la GPU la ha llevado a dominar el cómputo científico mundial:
- Década de 2000 (Alquimia Digital): Investigadores simulaban matrices de cálculo matemático camuflándolas como valores de píxeles RGB para engañar al hardware gráfico rígido.
- Folding@home (2006-2020): La red de cálculo distribuido doméstico de GPUs alcanzó picos de 1.5 exaflops durante el modelado molecular del virus SARS-CoV-2, superando a las supercomputadoras de IBM y la NASA juntas.
- El Cluster Condor (2010): La Fuerza Aérea de EE.UU. enlazó 1.760 consolas PlayStation 3 en red para procesar imágenes de satélite a bajo coste, validando la potencia del procesador gráfico Cell de consumo.
- El Momento AlexNet (2012): La red neuronal entrenada en dos tarjetas de consumo NVIDIA GTX 580 ganó el certamen ImageNet, dando inicio al actual renacimiento de la Inteligencia Artificial profunda y al posterior desarrollo de los núcleos Tensor dedicados.
Objetivos del Proyecto
- Objetivo General: Desarrollar una monografía detallada sobre el funcionamiento interno de la GPU moderna, justificando su transición desde un acelerador de vídeo a un procesador paralelo de propósito general.
- Objetivos Específicos:
- Explicar la diferencia entre las filosofías secuenciales de CPU y las paralelas de GPU basadas en modelos SIMD y SIMT.
- Analizar la función de los núcleos CUDA, Tensor de precisión mixta y aceleradores de Ray Tracing en la rasterización moderna.
- Describir las fases del pipeline gráfico y el subsistema VRAM ( GDDR6/GDDR6X, bus y frametime spikes).
- Evaluar las interfaces de conexión, disipación y alimentación en dGPUs y iGPUs.
- Estudiar las tecnologías de monitor (paneles IPS/VA/OLED) y ecosistemas de refresco adaptativo (G-Sync/FreeSync/VRR).